Алгоритм дедупликации
Finding — это результат одного сканирования, который содержит информацию об уязвимости. Finding считается родительским, если это является первой находкой для уязвимости, она создает issue.
Issue — это сущность в Vampy, которая содержит всю информацию об уязвимости, полученную из finding.
Finding считается duplicate, если во время импорта и работы алгоритма дедупликации была найдена совпадающая существующая issue. В этом случае дубликат finding связывается с issue.
Если дубликат определен, он связывается с issue и отображается в разделе Duplicate. Данные в issue берутся из родительской finding, дубликаты finding не обновляют их. Единственное поле, которое может быть обновлено — это solution.
Дедубликация — это алгоритм, который помогает Vampy распознавать идентичные issues в результатах сканирования.
Результат сканирования содержит несколько findings, которые включают в себя несколько полей, в зависимости от сканера. Обычно все сканы содержат repository name, branch name и внутренний дубликат отпечатка сканера — SD ID, но некоторые поля специфичны для различных видов сканеров.
| SAST | SCA | DAST |
|---|---|---|
| CVE | CVE | CVE |
| CWE | CWE | CWE |
| file path | file path | asset host |
| file line number | file line number | asset path |
| code snippet | library name | asset query |
| library version |
Основная проблема заключается в том, что не все сканеры заполняют эти поля, поэтому иногда мы можем получить несколько finding от разных сканеров, которые в основном ссылаются на одну и ту же issue. Для каждой finding Vampy создает несколько хешей на основе полей, которые содержит данная finding. Они используются для сравнения findings с существующими issues, чтобы выяснить, получили ли мы дубликат или нам нужно создать новую issue.
Таким образом, мы создаем следующие хеши для каждой finding
| Приоритет | SAST | SCA | DAST |
|---|---|---|---|
| 1 | repository + branch + SD ID (необходимо SD ID) |
repository + branch + product + artifact version + SD ID (необходимо SD ID) |
product + asset host + asset path + asset query + SD ID (необходимо SD ID) |
| 2 | repository + branch + CVE + CWE + filepath + code snippet (необходимы filepath и code snippet) |
repository + branch + product + artifact version + CVE + CWE + filepath + file line number + library name + library version (необходимы library name и library version) |
product + asset host + asset path + asset query + CVE + CWE (необходимо CVE) |
| 3 | repository + branch + CVE + CWE + filepath + file line number (необходимы filepath и file line number) |
repository + branch + product + artifact version + CVE + CWE + filepath + file line number + library name (необходимо library name, пустое для поиска library version) |
product + asset host + asset path + asset query + CVE + CWE + title |
| 4 | repository + branch + CVE + CWE + filepath + file line number + code snippet + title | repository + branch + product + artifact version + CVE + CWE + filepath + file line number + library name + library version + title |
Когда новые findings связываются с существующей issue, то и их хеши также связываются. В итоге мы имеем issue, которая имеет несколько хешей, полученных из всех findings, связанных с ней.
Примеры
SAST
Допустим, у нас есть 2 findings: A в качестве родительской и B как finding, которую нужно проверить на дубликат. У них есть все поля для SAST, A была найдена с помощью Semgrep, а B — с помощью Checkmarx. Как это выглядит в нашей системе? Красные стрелки показывают путь для наших примеров.
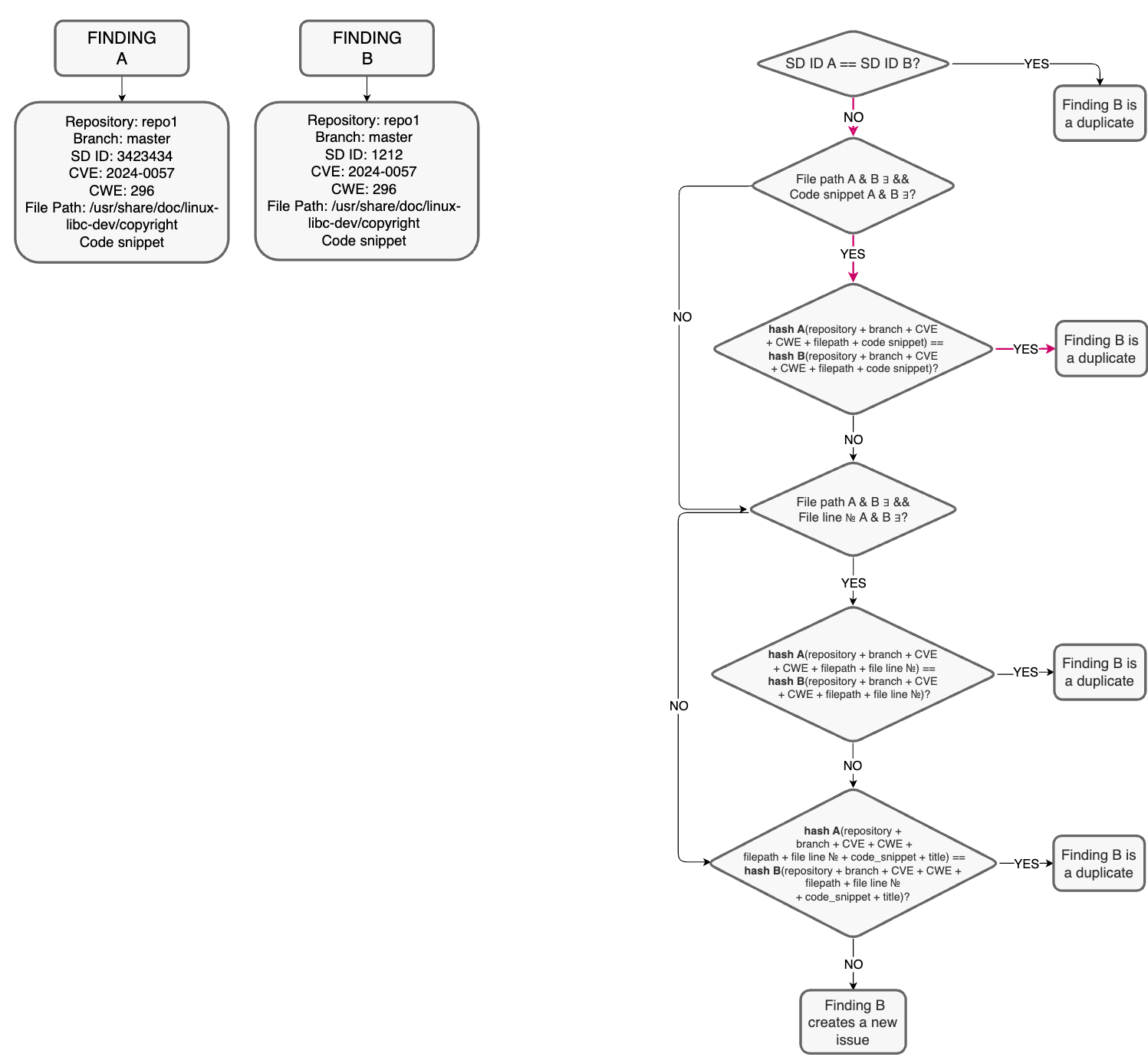
Здесь мы видим, что они не совпадают, поскольку у них разные отпечатки, полученные от разных сканеров. Но когда мы проверяем другие поля, мы понимаем, что это одна и та же issue.
SCA
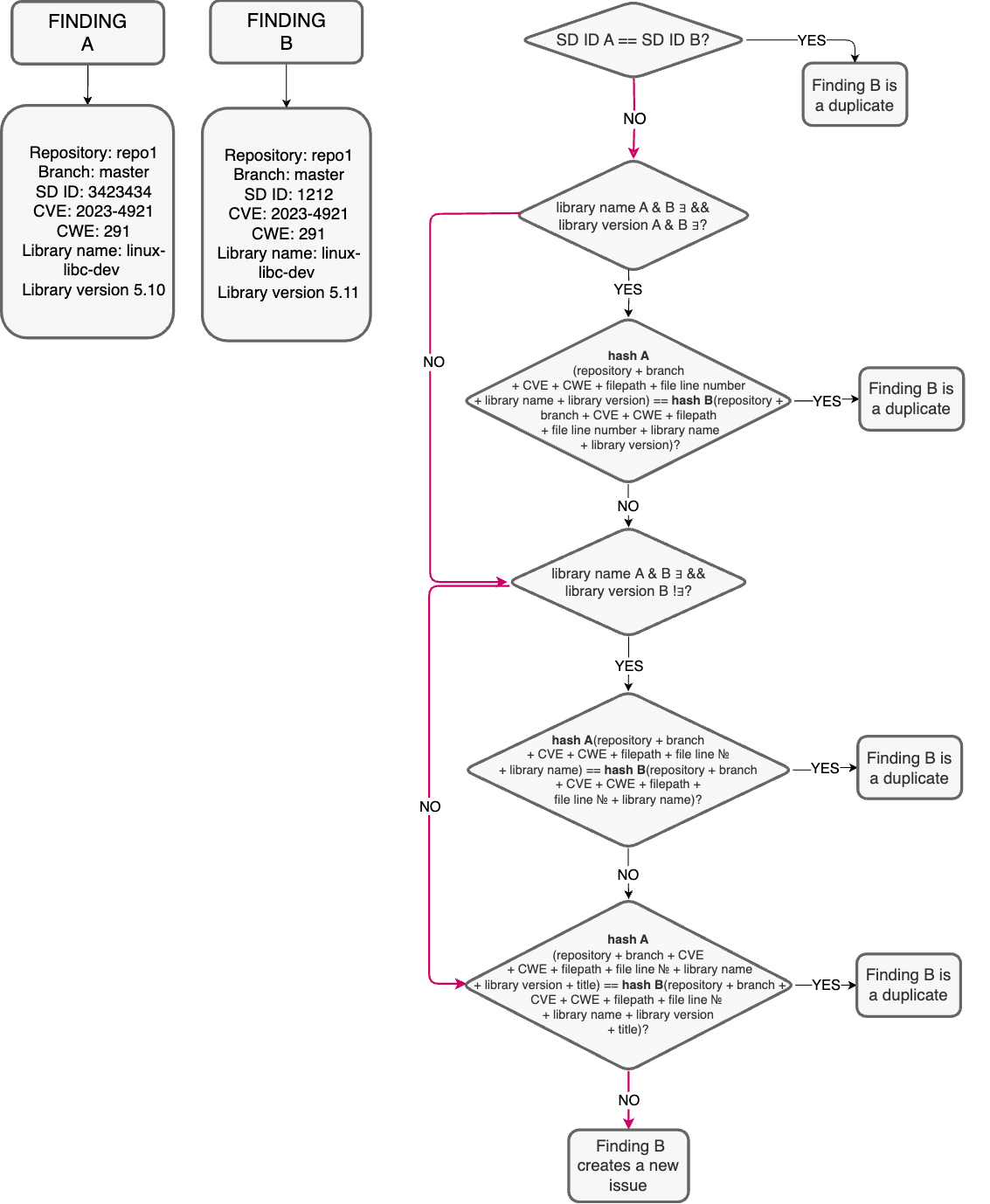
Мы нашли Finding A, с заполненными полями. Он описывает уязвимость в кусочке кода, поддерживаемом библиотекой версии 1.0. Мы обновили версию библиотеки до 1.1, но уязвимость никуда не делась, и следующий скан выявляет Finding B.
Схема выглядит довольно просто.
Автоматическое изменение статусов
При обработке нового скана платформа автоматически сравнивает:
- какие issues были найдены в текущей загрузке (как source finding или duplicate finding);
- какие issues раньше были в этом же контексте, но в текущей загрузке уже не встретились.
Контекст сравнения зависит от типа загрузки:
- репозиторий + ветка;
- продукт + репозиторий + ветка;
- продукт + актив;
- продукт + версия артефакта.
Дополнительно сравнение выполняется в рамках того же парсера/саб-парсера. То есть отсутствие дефекта в одном сканере не закрывает дефект, найденный другим сканером.
Исключение: если результаты разных сканеров уже были явно объединены дедупликацией в один issue (например, два SAST-инструмента нашли одну и ту же уязвимость по критериям дедупликации), автопереходы применяются к этому issue как к единой сущности.
Какие переходы выполняются автоматически
Если дефект найден в новом скане:
- New → Recurrent
- Fixed → Reopened
Если дефект не найден в новом скане:
- New → Fixed
- Recurrent → Fixed
- Reopened → Fixed
- Confirmed → Fixed
- Risk accepted → Fixed
Статусы False Positive и Check required автоматически не переводятся.